ky0422 블로그
Categories: Rust, TypeScript
들어가기 앞서
해당 Book은 Rust (러스트) 프로그래밍 언어의 중급 이상의 내용을 다루는 문서입니다. 이 Book은 가이드가 아닌, 참고 문서입니다. (각 문서는 별개임.)
Rust를 처음 접하는 분들은 Rust Book (한국어 번역)을 먼저 읽어보시기 바랍니다.
목차는 크게 Beginner (초급), Intermediate (중급), Advanced (고급)으로 나뉘어져 있습니다. Beginner는 비교적 쉬운 내용을 다루고 있으며, Intermediate 및 Advanced는 Rust의 기본적인 내용을 이해하고 있는 분들을 대상으로 합니다.
또한, Advanced는 CS (Computer Science)의 기본적인 내용을 이해하고 있는 분들을 대상으로 합니다.
Let's write!는 무언가를 만들어보는 과정입니다. 코드를 복사해도 되지만, 직접 작성해보는 것을 권장합니다.
목차
- Beginner
- Intermediate
- Advanced
- Let's write!
- 번외
- 비고
Beginner
클로저(closure)의 정체성
클로저를 다루다 보면 이런 식의 에러 메시지가 발생할 때가 있습니다:
...(...): [closure@src\...:n:n: x:xx]
보통 integer, bool 등의 타입 이름이 나오지만, 클로저는 위 형식과 같이 나옵니다.
일단 이 상황은 잠시 미뤄둬봅시다:
#![allow(unused)] fn main() { let mut foo = vec![]; foo.push(|| 1); foo.push(|| 2); }
당연히 작동할 것 같은 코드입니다만, 하지만 이 코드는 빌드되지 않습니다.
mismatched types
expected closure `[closure@src\main.rs:4:14: 4:18]`
found closure `[closure@src\main.rs:5:14: 5:18]`
no two closures, even if identical, have the same type
consider boxing your closure and/or using it as a trait object (rustc E0308)
main.rs(4, 14): the expected closure
main.rs(5, 9): arguments to this function are incorrect
mod.rs(1760, 12): associated function defined here
두 타입이 다르다는 오류가 우리를 반겨줍니다.
|| 1과 || 2는 분명 fn() -> i32 타입인데, 두 타입이 다르다니 참 아이러니한 상황일겁니다.
그에 대한 해답은, 클로저의 내부적인 구조를 보면 이해가 될겁니다.
rustc는 내부적으로 클로저를 각각 따로 구현합니다. 필자가 내부 구조를 알진 못하니, 일단 그렇게 알아둬봅시다.
실제로 클로저의 size_of_val은 0 입니다:
#![allow(unused)] fn main() { let x = || 1; println!("{}", size_of_val(&x)); // 0 let y = 1; println!("{}", size_of_val(&y)); // 4 let z = String::from("hello"); println!("{}", size_of_val(&z)); // 24 struct MyStruct; println!("{}", size_of_val(&MyStruct)); // 0 }
이 문제는 dyn으로 명시해서 해결해봅시다:
#![allow(unused)] fn main() { let x: &dyn Fn() -> i32 = &|| 1; println!("{}", size_of_val(&x)); // 16 }
#![allow(unused)] fn main() { let mut foo: Vec<&dyn Fn() -> i32> = vec![]; foo.push(&|| 1); foo.push(&|| 2); }
참고로 dyn (dynamic) 트레잇은 Sized가 아닌 타입(?Sized)입니다.
쉽게 말해, 컴파일 시간에 크기가 정해져 있지 않은 타입을 말합니다.
constant (상수)와 const fn
러스트엔 const 키워드가 있습니다. 이름 그대로 상수 선언 키워드며, 얼핏 보면 static item 키워드와 비슷해 보입니다.
주제는 const이기 때문에 static의 간단한 설명과 차이점만 보고 넘어갑시다:
#![allow(unused)] fn main() { static STATIC: &str = "Hello, World!"; const CONSTANT: &str = "Hello, World!"; }
둘 모두 &'static str 타입을 가지는 전역 범위에서 사용할 수 있는 상수입니다.
static: 수명이 있으며, 가변(mut)이 가능한 변수 (이 경우unsafe코드로 값을 변경할 수 있습니다.)const: 변경 불가능. (어떤 일이 있어도 변경할 수 없는 값입니다.)
const fn는 const 상수처럼 constant context의 일부입니다. (const impl 등도 이에 포함됩니다.)
이들의 특징은 컴파일 타임 상수 평가자(constant evaluation)가 컴파일 타임에 표현식을 계산합니다.
또한 이들은 for 반복문 등을 허용하지 않습니다. (후술하겠지만, 사실 for 문 그 자체가 문제는 아닙니다.)
그런데 while이나 loop 반복문은 사용할 수 있습니다. 이는 Iterator의 next 함수 때문입니다.
for 반복문은 Iterator의 next를 호출하여 순회합니다. 하지만 const fn 내부에선 const fn이 아닌 함수를 실행할 수 없습니다.
그렇기에 for 반복문을 사용할 수 없는 것이죠. 때문에 아래의 코드는 작동하지 않습니다:
const fn foo() -> i32 { let mut x = 0; loop { // work if x == 10 { break; } x += 1; } x } const fn bar() -> i32 { for x in 0..10 { // <- `for` is not allowed in a `const fn` ... if x == 10 { break; } } } const FOO: i32 = foo(); const BAR: i32 = bar(); fn main() { println!("{}", FOO); println!("{}", BAR); }
miri
추가로, 러스트의 constant context는 miri라는 컴파일러 내장되어있는 인터프리터가 평가합니다.
miri는 Undefined Behavior (UB) 가 일어나면 컴파일 에러를 띄워주기도 합니다.
평가가 완료되면 바이러니에 바이트채로 저장되어, static 등에 저장됩니다.
C++를 해보셨다면, const fn은 C++의 constexpr과 상당히 흡사하다는 걸 알 수 있습니다.
Default 트레잇
Default로 구조체, 열거형 타입 등에서 기본 값을 가져올 수 있습니다:
#![allow(unused)] fn main() { let (a, b, c, d): (usize, bool, String, Vec<i32>) = Default::default(); assert_eq!(a, 0); assert_eq!(b, false); assert_eq!(c, ""); assert_eq!(d, vec![]); }
Default 트레잇을 구현하면 됩니다:
#[derive(Debug)] struct Foo { x: i32, y: i32, } impl Default for Foo { fn default() -> Self { Foo { x: 0, y: 0 } } } fn main() { let foo = Foo::default(); let foo: Foo = Default::default(); assert_eq!(foo.x, 0); assert_eq!(foo.y, 0); }
이렇게 구현된 Default는 ..을 사용하여, 구현하지 않은 필드를 기본 값으로 채워줄 수 있습니다:
#![allow(unused)] fn main() { Foo { x: 1, ..Foo::default() }; Foo { x: 1, ..Default::default() }; }
<Default를 구현한 타입>::default(), Default::default() 모두 같은 역할입니다.
단, Default::default()의 경우엔 위 코드처럼 타입 어노테이션을 붙여줘 하는 경우도 있습니다.
열거형에서 Default
열거형(enum)의 경우엔 Default 트레잇 구현 없이 #[default] 속성(attributes)을 사용해 기본 값을 지정할 수 있습니다:
#[derive(Default, Debug)] enum Foo { A, #[default] B, } fn main() { println!("{:?}", Foo::default()); }
단, 빈 아이템만 가능합니다. B(String) 같은 건 안된다는 소리죠. (내부적으로 Default 트레잇을 구현하기 때문에 불가능)
열거형의 아이템이 일급객체가 아니여서, 빈 아이템이 아니라면 Default를 적용하지 못한다고는 하지만, 개인적인 생각이긴하나 Default 매크로를 좀 건들면 해결될 문제라 생각합니다.
Cow 타입
우리는 어떤 값이 참조인가, 아니면 소유권을 가지고 있는가에 대해 코드상으로 알고 싶을 때가 있습니다.
std::borrow에 존재하는 ToOwned라는 트레잇이 존재합니다.
ToOwned는 소유권이 있는 (owned) 타입으로 변환할 수 있는 트레잇입니다.
예를 들어, to_owned 함수를 사용하여, 참조 &str를 소유권이 있는 String으로 변환할 수 있습니다.
이를 이용해서 구현하면 좋을 듯한데, 이미 구현된 게 있으니: 바로 Cow
Copy On Write는 읽기만 필요한 경우, 굳이 대상을 다시 쓸 필요가 없으며, 수정이 있다면 그 대상을 새로 만드는 리소스 관리 기법입니다. (이 때문에 크기가 커질 수 있습니다.)즉,
Cow<T>는 읽기 전용입니다.
Cow<T> 열거형의 구현은 다음과 같습니다:
#![allow(unused)] fn main() { pub enum Cow<'a, B> where B: 'a + ToOwned + ?Sized, { Borrowed(&'a B), Owned(<B as ToOwned>::Owned), } }
제네릭 B는 수명 'a, ToOwned와 ?Sized로 바운드되어 있습니다.
B가 크기를 알 수 있는 타입인지 아닌지 모르니,?Sized가 포함되었습니다.
예를 들어봅시다. Borrowed엔 "Hello, World!", &'static str가 포함될 수 있습니다.
반면 String은 Owned에 포함됩니다. 그 이유는, ToOwned 트레잇에 대해 &str은 다음과 같이 구현되어 있습니다:
#![allow(unused)] fn main() { impl ToOwned for str { type Owned = String; fn to_owned(&self) -> String { unsafe { String::from_utf8_unchecked(self.as_bytes().to_owned()) } } fn clone_into(&self, target: &mut String) { // ... } } }
연관 타입(associated type) Owned가 String으로 명시되어 있습니다.
즉, String은 B (&'static str)의 Owned가 String이기 때문에, String은 Owned에 포함됩니다.
use std::borrow::Cow; fn foo(x: &str) -> Cow<'static, str> { if x == "foo" { Cow::Borrowed("bar") } else { Cow::Owned(x.to_string()) } } fn main() { match foo("foo") { Cow::Borrowed(x /* &str */) => println!("Borrowed: {x}"), Cow::Owned(x /* String */) => println!("Owned: {x}"), } match foo("baz") { Cow::Borrowed(x /* &str */) => println!("Borrowed: {x}"), Cow::Owned(x /* String */) => println!("Owned: {x}"), } }
이런 방법으로, 위에서 서술한 참조인가, 아니면 소유권을 가지고 있는 (owned) 값인가에 대해 알 수 있습니다.
Hash 트레잇, Hasher, DefaultHasher
러스트 표준 라이브러리엔 해싱을 지원하는 모듈이 존재합니다. (std::hash)
말 그대로 해싱을 지원하며, 구조체에 Hash 트레잇을 사용할 수 있습니다:
use std::{collections::hash_map::*, hash::*}; #[derive(Hash, Debug)] struct Foo(usize); fn hash<T: Hash>(t: &T) -> u64 { let mut hasher = DefaultHasher::new(); t.hash(&mut hasher); hasher.finish() } fn main() { let foo = Foo(30); println!("{:?}", hash(&foo)); let bar = Foo(30); println!("{:?}", hash(&bar)); }
위 코드는 똑같은 u64 크기의 값을 출력합니다. 누가봐도 Hash의 모습이지만, 코드를 이해하는 것도 중요합니다.
먼저 위 코드는 다음과같이 작성할 수 있습니다:
#![allow(unused)] fn main() { // 생략 #[derive(Debug)] struct Foo(usize); impl Hash for Foo { fn hash<H: Hasher>(&self, state: &mut H) { self.0.hash(state); } } // 생략 }
#[derive(Hash)] 는 내부적으로 위와 같이 구현됩니다. Hasher는 또 뭘까요?
Hasher
말 그대로 해시하기 위한 트레잇입니다. 이 트레잇에는 write_*, finish 등의 메서드가 존재합니다.
실제로 위 코드에서 finish가 호출된것을 볼 수 있습니다. Hasher는 다음과 같이 작동합니다.
DefaultHasher등으로Hasher를 만듭니다.write,write_*(write_u8,write_str등)을 호출하여Hasher에 데이터를 씁니다.- finish로 마무리하여, 여태 썼던 해시를 반환합니다.
DefaultHasher는 RandomState을 사용합니다. 이 글에선 다루지 않으니, 궁금하다면 문서를 참조하면 됩니다.
위에선 write 대신 hash 함수를 사용했는데, 이는 Hash 트레잇에 내장되어있습니다.
hash 함수는 값을 해시하여, 가변 Hasher 참조에 write 합니다.
Hash 트레잇은 대부분의 기본 타입 (str, char, u8, bool 등)에 구현되어 있습니다.
만약 sha256 등의 다른 Hasher를 사용하고 싶다면, 다른 개발자가 만든 크레이트를 사용하면 됩니다.
From, TryFrom (Feat. Into, TryInto)
From 트레잇을 사용하면, 다른 타입을 대상 타입으로 변환할 수 있습니다.
이미 많이 사용해왔던 기능인데, String::from("foo") 등으로 사용해왔던 트레잇입니다:
#![allow(unused)] fn main() { use std::convert::*; #[derive(Debug, PartialEq)] struct Foo { bar: usize, } impl From<usize> for Foo { fn from(item: usize) -> Self { Foo { bar: item } } } let x = Foo::from(5); assert_eq!(x, Foo { bar: 5 }); }
하지만 Box<T>같은 타입은 new 메서드를 사용해서 Box를 생성할 수 있습니다. (물론 From 트레잇도 구현되어 있으나, 둘 모두 같은 기능을 합니다.)
그럼 왜 굳이 From 트레잇을 구현하는가 하면, 매우 간단명료하게 대답할 수 있습니다:
Box의 new와 from은 제네릭 T를 받고, from은 new를 호출한합니다.
(제네릭 T를 받지 않는 타입 (ex; String) 같은 경우, new 보단 from이 더욱 편합니다.)
그러므로 new와 from 메서드의 기능은 똑같지만, 후술할 Into 덕분에 from이 존재합니다.
Into
Into는 From을 구현하면 자동으로 구현됩니다. 다만, 사용 방법이 조금 다릅니다:
#![allow(unused)] fn main() { use std::convert::*; #[derive(Debug, PartialEq)] struct Foo { bar: usize, } impl From<usize> for Foo { fn from(item: usize) -> Self { Foo { bar: item } } } let x = Foo::from(5); assert_eq!(x, Foo { bar: 5 }); let x: Foo = 5usize.into(); assert_eq!(x, Foo { bar: 5 }); }
into를 사용할 땐, 컴파일러가 어떤 타입인지 모르기 때문에, 타입 어노테이션을 명시해주어야 합니다.
TryFrom, TryInto
관련 자료 등을 찾아보면 TryFrom과 TryInto가 존재하는 것을 알 수 있는데, 이들은 이름 그대로 반환되는 값이 Result<T, E>의 경우일 때 사용합니다.
대표적으로, 타입 변환을 사용할 때 이용됩니다:
#![allow(unused)] fn main() { let x: Result<i64, _> = 5i32.try_into(); }
타입으로 쓰인 _는 반환 값을 무시하는 _ = expr; 문법이 아닌, infer 타입을 뜻합니다.
TryFrom 또한, From 트레잇과 비슷하게 구현할 수 있습니다:
#![allow(unused)] fn main() { use std::convert::*; #[derive(Debug, PartialEq)] struct Foo { bar: usize, } impl TryFrom<usize> for Foo { type Error = &'static str; fn try_from(value: usize) -> Result<Self, Self::Error> { if value != 0 { Ok(Foo { bar: value }) } else { Err("Error") } } } let x = Foo::try_from(5); assert_eq!(x, Ok(Foo { bar: 5 })); let x = Foo::try_from(0); assert_eq!(x, Err("Error")); let _: Foo = 5usize.try_into().unwrap(); }
다만 차이점은, Error라는 연관 타입(associated type)이 존재하는데, 그냥 Result<T, E>의 제네릭 E 입니다.
#[inline] 속성
일단 inline 함수가 무엇인지부터 알아봐야 합니다.
이는 본래 C/C++에서 유래되었는데, C/C++의 inline과 상당히 비슷합니다.
inline 함수의 작동 원리를 보기 전에, 일반적인 함수가 어떻게 작동하는지부터 알아봐야 하는데, 일반적으로 함수가 호출되면, 함수가 존재하는 코드로 점프하고, 실행이 끝나면 다시 원래 위치로 돌아옵니다.
여기서 inline 함수의 차이점이 들어납니다: inline 함수는 함수의 코드를 함수를 호출하는 부분에 복사합니다.
이는 매크로와 유사해보이는데, inline 함수는 개발자 입장에서 일반적인 함수와 똑같습니다만, 내부적으론 다릅니다.
물론 inline 함수를 많이 사용하는 것은 오히려 독이 될 수 있습니다: 많은 inline 함수를 호출하면, 그 많은 코드가 복사된다는 뜻이고, 이는 곧 느려질 수 있다는 뜻이죠.
그럼 이 inline 함수는 언제 써야 할까요? 사실 개발자가 직접 inline을 명시해주는 것은 그다지 좋은 선택이 아닙니다.
러스트 컴파일러는 알아서 inline을 사용할지 말지 결정합니다.
이 부분에 대해선 우리보다 컴파일러가 더 똑똑하니, 굳이 명시해줄 필요는 없습니다.
그래도 굳이 쓰고싶다면 ...
러스트엔 inline 함수를 명시해주는 속성이 있습니다: #[inline(..)]
크게 #[inline], #[inline(always)] 그리고 #[inline(never)]가 존재하는데, 각각 하는 일은 다음과 같습니다:
#[inline]: inline 함수가 되어야 함을 명시합니다. 항상inline되는 것은 아닌데, 이 또한 컴파일러가 결정합니다.#[inline(always)]:#[inline]보다 더 강력하게inline함수가 되어야 함을 명시합니다. 물론 항상 inline 함수가 되진 않습니다.#[inline(never)]: inline 함수가 되면 안된다는 것을 명시합니다.
이러한 #[inline] 속성은 new와 같은 함수같은 단순한 함수에 주로 사용됩니다:
#![allow(unused)] fn main() { struct Foo(u8); impl Foo { #[inline] fn new(x: u8) -> Self { Foo(x) } } }
&'static T와 T: 'static의 차이점
특히 러스트 초보(= 입문자)분들이 흔히들 오해를 하는데, 이 둘은 생긴것만 비슷하게 생겼고, 동작은 다릅니다.
&'static T는 참조의 정적 수명입니다. 이 글을 방문했다는건 정적 수명에 대해 대부분 알고있을거라 생각합니다.
이름이 비슷한 T: 'static은 트레잇 바운드입니다.
이것은 T가 정적 라이프타임을 가지고 있지 않으면, 제한하는 트레잇 바운드입니다.
fn foo<T: 'static>(_x: T) {} static X: i32 = 5; fn main() { let x: &'static str = "Hello, World!"; foo(x); foo(X); let y = 5; foo(&y); // error }
이 코드에서 x와 X는 'static 수명을 가지기 때문에, 아무런 문제가 없었습니다.
반면 y의 참조는 'static 수명을 가지고 있지 않기 때문에, 오류가 발생합니다.
요약
&'static T와 T: 'static은 다르며, 전자는 정적 수명을 가짐을 명시, 후자는 정적 수명을 가지고 있지 않으면 그것을 제한하는 트레잇 바운드입니다.
Intermediate
함수 오버로딩 구현하기
유감스럽게도 러스트엔 함수 오버로딩(overloading), default parameter, optional parameter 등이 없습니다.
하지만 오버로딩은 대충 구현해볼 수 있습니다:
#![allow(unused)] fn main() { struct Overloading; trait Foo<T> { type Output; fn ctor(arg: T) -> Self::Output; } }
이렇게 선언된 구조체와 트레잇을 이용하여 함수 오버로딩을 사용할 수 있습니다:
#![allow(unused)] fn main() { impl Foo<usize> for Overloading { type Output = usize; fn ctor(arg: usize) -> Self::Output { arg * 10 } } impl Foo<String> for Overloading { type Output = String; fn ctor(arg: String) -> Self::Output { arg + "!" } } }
ctor은constructor를 의미합니다. 이 예제에선ctor라는 네이밍을 사용했습니다.
이런 식으로 제네릭 T엔 인자 타입, 연관 타입(associated type) Output을 구현하여, 오버로딩을 흉내 낼 수 있습니다.
이제 헬퍼(Helper) 함수를 이용해서 편리하게 호출할 수 있습니다:
#[inline] fn foo<T>(arg: T) -> <Overloading as Foo<T>>::Output where Overloading: Foo<T>, { <Overloading as Foo<T>>::ctor(arg) } fn main() { println!("{}", foo(2)); println!("{}", foo(String::from("Hello"))); }
번외로, 여기서 #[inline] 속성이 사용되었습니다. 이에 대한 글은 이곳을 참고해봅시다.
다만 복수 개의 인자를 받을 수는 없습니다. 그럴땐 튜플을 사용하거나 매크로를 사용해봅시다:
#![allow(unused)] fn main() { impl Foo<(usize, usize)> for Overloading { type Output = usize; fn ctor(arg: (usize, usize)) -> Self::Output { arg.0 + arg.1 } } println!("{}", foo((2, 3))); }
#![allow(unused)] fn main() { macro_rules! foo { ($arg:expr) => { $arg * 10 }; ($a:expr, $b:expr) => { $a + $b }; } assert_eq!(foo!(2), foo!(15, 5)); }
모나드 bind 함수 구현하기
먼저 모나드가 뭔지 모른다면, 구글링을 해보도록 합시다.
금붕어도 이해할 만큼 쉽게 설명하면, Option<T>, Result<T, E> 같은게 모나드입니다.
자세한건 생략하겠지만, 물론 이게 모나드의 전부가 아닙니다.
사실 필자도 모나드에 대해서 자세하게 아는건 아닙니다.
이 글에선 모나드의 강력한 기능중 하나인 bind (하스켈에선 >>= 연산자) 를 구현해보고자 합니다.
러슬람들은 트레잇을 참 좋아합니다. 트레잇을 선언하고, 그 트레잇을 구현해봅시다:
#![allow(unused)] fn main() { pub trait Monad { type T; type U; fn bind<F>(self, f: F) -> Self::U where F: FnOnce(Self::T) -> Self::U; } }
type T는 bind의 인자가 받는 함수(f)의 인자이며, type U는 bind와 f의 반환값입니다.
이렇게만 말하면 뭔말인지 이해가 힘드니, 직접 구현해보며 이해해봅시다:
#![allow(unused)] fn main() { impl<T> Monad for Option<T> { type T = T; type U = Option<T>; fn bind<F>(self, f: F) -> Self::U where F: FnOnce(Self::T) -> Self::U, { match self { Some(x) => f(x), None => None, } } } }
Option<T>에 대한 Monad 구현입니다. bind 함수를 봅시다.
만약 self (Option<T>)가 Some<T> 이면, 함수 f를 실행하며, 아니라면 그냥 None을 반환합니다.
이제 한층 더 편한 러스트 프로그래밍을 할 수 있습니다:
#![allow(unused)] fn main() { assert_eq!(Some(10).bind(|x| Some(x * 10)), Some(100)); assert_eq!(None::<usize>.bind(|x| Some(x * 10)), None); let (mul_5, div_10) = (|x: usize| Some(x * 5), |x: usize| Some(x / 10)); assert_eq!(Some(10).bind(mul_5).bind(div_10), Some(5)); }
?Trait 바운드와 marker 타입
? (물음표) 트레잇 바운드는 트레잇이 선택 사항임을 표시하는 문법입니다.
trait X {} struct A; impl X for A {} struct B; fn foo<T>(_x: T) where T: ?X {} fn main() { foo(A); foo(B); }
만약 T: ?X가 아닌, T: X 였다면, 오류가 발생했을 것입니다:
the trait bound `B: X` is not satisfied
the trait `X` is implemented for `A`
보통 ?Sized등의 marker 타입으로 ? 트레잇 바운드를 사용해보았을 겁니다:
fn foo<T>(x: &T) where T: ?Sized + std::fmt::Debug, { println!("{x:?}"); } fn main() { let x = 42; foo(&x); }
Sized는 컴파일 타임에 알려진 크기의 타입입니다.
예를 들어 [usize; 3]은 크기가 3이라는 알려진 타입입니다.
하지만 [usize]는 컴파일 타입에 길이가 얼만지 모릅니다.
보통
str이나[T]등의 알려지지 않은 크기의 타입을DST(Dynamically Sized Type)이라고 부릅니다.
이럴 때 ?Sized를 사용하여 컴파일 타임에 알려지지 않은 크기의 타입을 취급할 수 있습니다:
#![allow(unused)] fn main() { struct Foo<T>(T) where T: ?Sized + std::fmt::Debug; struct FooBar(Foo<[usize]>); }
아까부터 marker 타입이 언급됐습니다.
요약
marker 타입은 정말 간단하게 말해서, 어떤 타입의 속성을 나타내는 구조체, 트레잇 등의 빈 타입입니다.
러스트의 타입은 고유한 속성에 따라, 다양한 방식으로 분류됩니다.
그러한 속성을 표시(명시)해주는 타입입니다.
위에서 언급한 Sized도 marker 타입이며, 구조체로 이루어진 PhantomData, PhantomPinned, 트레잇으로 이루어진 Copy, Send, Sync, Sized, Unpin도 marker 타입입니다. (자세한 사항은 여기에서 확인할 수 있습니다.)
위 ? 트레잇 바운드와 반대로, 부정 트레잇 바운드도 존재합니다: ! (느낌표)
이가 대표적으로 사용되는 예는 Rc<T> 입니다.
Rc<T>에서는 Send와 Sync을 구현하면 안 됩니다. (자칫하다간 데이터 레이스가 발생할 수 있기 때문)
때문에 Rc<T>의 구현을 보면
#![allow(unused)] fn main() { impl<T> !Send for Rc<T> where T: ?Sized { /* ... */ } impl<T> !Sync for Rc<T> where T: ?Sized { /* ... */ } }
처럼 구현된 것을 볼 수 있습니다. 반면 Arc의 구현을 보면 Send와 Sync이 구현되어 있는 것을 확인할 수 있습니다:
#![allow(unused)] fn main() { impl<T> Send for Arc<T> where T: Sync + Send + ?Sized { /* ... */ } impl<T> Sync for Arc<T> where T: Sync + Send + ?Sized { /* ... */ } }
Any 트레잇과 TypeId
Any 트레잇은 모든 'static 타입의 동적 타이핑을 가능케 하는 트레잇입니다.
'static은 수명 'static과 트레잇 바운드 'static이 존재합니다. 자세한 내용은 이 글을 참고해봅시다.
여기서 서술하는 'static은 트레잇 바운드 'static을 의미합니다.
Any 타입을 사용하는 예제:
#![allow(unused)] fn main() { use std::any::Any; let x: Box<dyn Any> = Box::new(1); let y: &dyn Any = &1; }
Any는 컴파일 타임에 크기를 알 수 없습니다. 때문에 dyn 접두사를 사용하며, Box 또는 'static 참조를 사용합니다.
Any 타입을 사용하는 다른 예제:
#![allow(unused)] fn main() { use std::{any::Any, fmt::Display}; fn foo<T: Any + Display>(x: &T) { match (x as &dyn Any).downcast_ref::<i32>() { Some(v) => println!("i32: {v}"), None => println!("unknown: {x}"), } } foo(&1); foo(&"hello"); }
여기서 downcast_ref를 사용하였습니다.
downcast_mut 등의 여러 API가 존재하는데, 각자 하는 역할은 다음과 같습니다:
downcast<T>: 이는Box<...>에 대해 구현되어 있습니다.Box를downcast하며,Result<T, E>를 반환합니다.downcast_ref<T>:dyn Any+'static에 구현되어 있습니다. 내부 값이T타입과 일치한다면, 그것에 대해 참조를 반환합니다.Option<T>를 반환하며, 일치하지 않다면None을 반환합니다.downcast_mut<T>: 위downcast_ref와 동일하며, 가변 참조를 반환합니다.
이밖에도 is 함수 등이 구현되어 있지만, 이 글에선 서술하지 않습니다. 자세한 내용은 이곳을 참고해봅시다.
TypeId
TypeId는 타입에 대해 고유한 식별자를 나타냅니다. 위에서 서술하진 않았지만, 타입을 비교하는 is 함수는 다음과 같이 정의되어 있습니다:
#![allow(unused)] fn main() { pub fn is<T: Any>(&self) -> bool { let t = TypeId::of::<T>(); let concrete = self.type_id(); t == concrete } }
대충 보면 is의 사용 방법을 알 것입니다. 하지만 is의 사용 방법을 서술하진 않았으니, TypeId 부분을 봅시다.
Any 트레잇은 TypeId를 반환하는 type_id라고 하는 함수를 구현하고 있습니다.
위는 TypeId::of::<T>()를 사용하여, 두 TypeId가 일치하는지 검사하는 함수입니다.
사실상 TypeId의 주요 기능은 이게 전부입니다.
이밖에도 Provider와 Demand가 존재하지만 깊이 들어가는 기능이기도 하고, 무엇보다 실험적 기능이므로 이 글에선 서술하지 않습니다.
혹시라도 궁금하다면 이곳을 참고해봅시다.
절차적 매크로, syn, quote, Attribute
절차적 매크로는 함수(procedure)처럼 생겼다고 해서 절차적 매크로(procedural macro)입니다.
#[foo(bar = 10)] 등의 모습은 속성이며, 이는 Attribute (속성) 문법입니다. 여기서 만들 절차적 매크로는 #[derive(Foo)] 등의 Derive 속성입니다.
일반적인 매크로와의 차이점이라 하면, 일반적인 매크로는 패턴에 맞게 대치하는 반면, 절차적 매크로는 코드를 추가합니다.
절차적 매크로를 만들기위해, proc-macro (절차적 매크로) 크레이트를 생성해줍니다.
왜 따로 절차적 매크로 크레이트를 분리해야 하냐는 질문이 분명 있을 겁니다:
절차적 매크로 크레이트는 일반적인 크레이트처럼 생겼지만, 컴파일 시 문법 (AST 등)를 수정한다는 점에서, 일반적인 크레이트 보단 컴파일러 플러그인 정도에 가깝습니다.
이에 대해 한 가지 더 재밌는 사실을 알 수 있는데, 절차적 매크로 크레이트는, 빌드 시 절차적 매크로가 아닌 크레이트들과 연결되지 않습니다. 때문에, 굳이 타겟 아키텍처에 맞게 빌드할 필요는 없습니다.
오늘의 예제 프로젝트 구조는 다음과 같습니다.
(예제를 무시하고 절차적 매크로 선언만 보고 싶다면, 무시해도 괜찮습니다.):
/foo크레이트- ``/src`
main.rs
Cargo.toml
- ``/src`
/foo_derive(절차적 매크로 크레이트)/srclib.rs
Cargo.toml
먼저 아래의 명령어를 입력하여, 크레이트를 생성해줍니다.:
$ cargo new foo --bin
$ cargo new foo_derive --lib
foo 크레이트의 Cargo.toml에서 foo_derive 의존성을 추가해주어야 합니다:
[dependencies]
foo_derive = { path = "../foo_derive" }
또한, 절차적 매크로는 proc-macro를 따로 추가해주어야 합니다. foo_derive 크레이트의 Cargo.toml:
# 생략
[lib]
proc-macro = true
rust analyzer 등을 사용한다면, foo_derive 크레이트에서 오류가 발생할 것입니다. 이는 매우 정상적이며, 절차적 매크로 크레이트에선 절차적 매크로만 선언되어야 합니다.
syn과 quote
그리고 몇 가지의 크레이트가 더 필요한데, syn 크레이트와 quote 크레이트가 필요합니다. 각각의 크레이트가 하는 일은 다음과 같습니다:
syn:TokenStream을 분석합니다. 또한, 우리가 러스트 코드에서 사용할 수 있는 AST 관련 데이터 등을 제공합니다.quote: 러스트 코드를 받아,TokenStream으로 반환합니다.
각 크레이트에 대해 자세히 알고 싶다면, 각 크레이트의 문서를 참고하길 바랍니다.
필자는 현재의 최신 버전인 syn 1.0.102, quote 1.0.21를 사용합니다:
[dependencies]
quote = "1.0.21"
syn = "1.0.102"
이제 준비는 끝났습니다. 절차적 매크로 선언은 다음과 같습니다:
#![allow(unused)] fn main() { use proc_macro::TokenStream; #[proc_macro_derive(FooMacro)] pub fn foo_macro(input: TokenStream) -> TokenStream { input } }
이 아직 코드는 무의미합니다. 이제 아까 추가해두었던 syn과 quote를 사용해봅시다.
우리가 만들 절차적 매크로는, FooMacro를 호출하면 Person 트레잇을 구현해주는 절차적 매크로입니다.
foo 크레이트의 main.rs:
use foo_derive::FooMacro; trait Person { fn say_hello(&self); } #[derive(FooMacro)] struct A { name: String, } fn main() { let a = A { name: "John".to_string(), }; a.say_hello(); }
이제 syn과 quote 크레이트가 필요합니다. syn의 parse_macro_input 매크로를 이용해서, TokenStream을 분석합니다:
foo_derive 크레이트의 lib.rs:
#![allow(unused)] fn main() { use proc_macro::TokenStream; use quote::quote; use syn::{parse_macro_input, DeriveInput}; #[proc_macro_derive(FooMacro)] pub fn foo_macro(input: TokenStream) -> TokenStream { let DeriveInput { ident, .. } = parse_macro_input!(input as DeriveInput); let result = quote! { impl Person for #ident { fn say_hello(&self) { println!("Hello, my name is {}", self.name); } } }; result.into() } }
여기서 DeriveInput 구조체는 다음과 같은 필드가 존재합니다:
attrs:#[foo]같은 속성을 뜻합니다.vis:pub,pub(crate)같은 가시성을 뜻합니다.ident: 그 아이템의identifier(식별자)를 뜻합니다.generics: 제네릭 또는where절을 뜻합니다.data:구조체의 경우 필드 등을 뜻합니다. (struct,enum,union)
여기서 우리가 사용한 것은 ident 입니다.
그리고 우리는 quote 크레이트를 사용하여, quote 매크로를 호출했습니다.
만약 quote 크레이트 없었다면, 우리는 직접 AST를 하나하나 구현했어야 했을 겁니다.
다행히 quote! {} 매크로는 TokenStream을 반환하므로, into를 호출하여 반환한다.
이제 foo 크레이트를 실행하면, 성공적으로 "Hello, my name is John" 이 출력되었을 것입니다.
예상했겠지만, Debug, Default 등의 매크로도 위와 같은 원리입니다. (물론 이들은 built-in이긴 합니다만)
실제로 Debug의 예시로, 아래의 둘 모두 똑같이 작동합니다:
#![allow(unused)] fn main() { #[derive(Debug)] struct Foo { bar: usize } }
만약, Debug 매크로가 없었다면, 우리는 아래와 같이 일일이 구현해주었어야 할 것입니다:
#![allow(unused)] fn main() { struct Foo { bar: usize, } impl std::fmt::Debug for Foo { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("Foo").field("bar", &self.bar).finish() } } }
아까 우리는 DeriveInput에서 attrs가 존재하는 것을 확인했습니다.
속성(attrs)을 손수 만들어보고 싶은데, syn만 이용해선 힘들 겁니다.
이제, darling 크레이트를 사용해봅시다.
darling
그리 유명한 크레이트는 아니나, darling 크레이트는 속성을 쉽게 파싱 할 수 있는 유용한 크레이트입니다.
필자는 가장 최신 버전인 0.14.1을 사용했습니다:
#![allow(unused)] fn main() { [dependencies] darling = "0.14.1" quote = "1.0.21" syn = "1.0.102" }
darling 크레이트는 FromDeriveInput 절차적 매크로와, 그에 따른 darling 속성을 이용하여, attrs를 파싱 할 수 있습니다:
#![allow(unused)] fn main() { use darling::FromDeriveInput; use proc_macro::TokenStream; use quote::quote; use syn::{parse_macro_input, DeriveInput}; #[derive(FromDeriveInput, Default)] #[darling(default, attributes(nickname))] struct Attributes { nickname: Option<String>, } #[proc_macro_derive(FooMacro, attributes(nickname))] pub fn foo_macro(input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); let attrs = Attributes::from_derive_input(&input).unwrap(); let DeriveInput { ident, .. } = input; let my_name = match attrs.nickname { Some(nickname) => quote! { fn say_hello(&self) { println!("Hello, my name is {}, but you can call me {}.", self.name, #nickname); } }, None => quote! { fn say_hello(&self) { println!("Hello, my name is {}.", self.name); } }, }; let result = quote! { impl Person for #ident { my_name } }; result.into() } }
코드가 좀 복잡해졌습니다. 하지만 수정하기 전의 코드에서 조금의 코드만 추가되었을 뿐입니다.
FromDeriveInput를 사용했다면, proc_macro_derive 속성에도 attributes를 추가하여 이런 하위 속성이 있다고 명시해주어야 합니다.
그런데 만약 Attributes에서 Option<T>를 사용하지 않으면 어떻게 될까요?
눈치가 빠른 독자라면 Default 트레잇이 적용되었기 때문에, 빈 문자열이 반환됩니다. 이것을 방지하기 위해, Option<T>를 사용했습니다. 생각하지 못했다고 실망하진 맙시다.
이제 다음과 같은 코드가 가능해졌습니다:
use foo_derive::FooMacro; trait Person { fn say_hello(&self); } #[derive(FooMacro)] struct A { name: String, } #[derive(FooMacro)] #[nickname(nickname = "Bob")] struct B { name: String, } fn main() { let a = A { name: "John".to_string(), }; a.say_hello(); let b = B { name: "John".to_string(), }; b.say_hello(); }
for<'a> (상위 트레잇 바운드 HRTB)
들어가기 앞서, 참고로 여기서 for은 반복문 또는 트레잇 구현 키워드가 아닙니다.
Higher Rank Trait Bounds (HRTB) 키워드입니다.
한국어로 직역하면 상위 트레잇 바운드인데, 일단 이는 잠시 저장해두고 아래의 예제를 보도록 합시다.
trait Foo<F> { fn foo(&self, f: F) -> &usize; } struct Bar((usize, usize)); impl<T> Foo<T> for Bar where T: Fn(&(usize, usize)) -> &usize, { fn foo(&self, f: T) -> &usize { f(&self.0) } } fn main() { let bar = Bar((5, 10)); let x = bar.foo(|s| &s.0); println!("{x}"); }
제네릭 F 타입의 파라미터 f를 갖는 foo를 갖는 트레잇 Foo와,
(usize, usize) 튜플 타입의 튜플을 받는 Bar 구조체가 구현되어있습니다.
아래에서 구현된 제네릭 F는 Fn(&(usize, usize)) -> usize로 트레잇 바운드를 해주었습니다.
foo 함수는 인자 f를 실행하는 고차 함수입니다.
즉, main 함수에서 foo를 호출하여 Bar의 튜플에서 0번째 인덱스의 값을 가져오는 코드입니다.
for 라이프타임
위 코드는 작동엔 문제 없으나, 어떠한 이유에서든 F에 수명을 명시하고 싶을 때가 있습니다.
#![allow(unused)] fn main() { T: <'a> Fn(&'a (usize, usize)) -> &'a usize }
하지만 이러한 코드는 작동하지 않습니다. 이럴 때 쓰이는 것이 for<'a>입니다.
#![allow(unused)] fn main() { T: for<'a> Fn(&'a (usize, usize)) -> &'a usize // 또는 for<'a> T: Fn(&'a (usize, usize)) -> &'a usize }
놀랍게도 이게 끝입니다. 심지어 Fn 계열 트레잇 외엔 많이 쓰이지도 않습니다.
Advanced
Pin과 Unpin
Pin은 Pin<T>에서 (T는 포인터) T가 가리키는 내용이 Unpin을 구현하지 않는 한 T가 이동되지 않도록 보장하는 스마트 포인터입니다.
T는 이동(move)할 수 있는 포인터만 유효합니다. 만약 T가 Unpin을 구현하고 있다면, Pin이 비활성화 됩니다.
대부분 Unpin은 자동으로 구현됩니다. 물론 PhantomPinned 같은 경우엔 예외입니다.
Pin을 설명하기 전에, 이동에 대해 잠시 보도록 합시다:
fn main() { let s = String::from("hello"); let s1 = s; // 이 시점에서 s는 유효하지 않다. println!("{}", s1); }
이동(move)은 우리와 너무나도 친숙한 존재일겁니다.
이동은 러스트를 배우지 않았다면 불편한 존재지만, 러스트를 배우고 다시 보면 러스트의 자랑스러운 기능 중 하나 일 것입니다.
하지만 이런 이동이 일어나지 않아야 할 상황이 있습니다. 바로 **자기 참조 구조(self reference structure)**입니다:
use std::ptr; struct Foo { foo: usize, bar: *mut usize, } impl Foo { pub fn new(foo: usize) -> Foo { Foo { foo, bar: ptr::null_mut() } } pub fn init(&mut self) { self.bar = &mut self.foo; } pub unsafe fn get_mut(&self) -> &mut usize { &mut *self.bar } } fn main() { let mut foo = Foo::new(1); foo.init(); let foo_mut = unsafe { foo.get_mut() }; *foo_mut = 5; println!("{}", foo_mut); }
보통 이런 모습을 자기 참조 구조라 부릅니다.
위 코드에서 get_mut()은 foo의 참조가 아닌 bar에 저장해둔 참조를 반환합니다.
이 코드는 잘 작동하지만, 조금만 수정해봅시다:
// 생략 fn foo() -> Foo { let mut foo = Foo::new(1); foo.init(); foo } fn main() { let f = foo(); let foo_mut = unsafe { f.get_mut() }; *foo_mut = 5; println!("{}", foo_mut); }
이걸 실행해보면 이상한 값이 나오는데, bar가 foo 함수에서의 스택을 가리키고 있기 때문에, Undefined Behavior (UB) 가 발생합니다. 이미 해제된 메모리를 역참조하였기 때문이죠.
예를 들어, 어떤 객체가 0x0001에 위치해있고, 그 객체를 가리키는 포인터가 있다고 가정합시다.
만약 그 객체가 재배치 되어, 임의의 위치 0x0002로 이동하였다면 상당히 곤란하겠죠.
이 문제의 해결 방법은 이동해도 변하지 않는 주소일 때만 참조를 저장해야 합니다.
Pin은 그 문제를 해결해줍니다:
Pin
use std::{marker::*, pin::*, ptr}; struct Foo { foo: usize, bar: *mut usize, _pin: PhantomPinned, } impl Foo { pub fn new(foo: usize) -> Foo { Foo { foo, bar: ptr::null_mut(), _pin: PhantomPinned } } pub fn init(self: Pin<&mut Self>) { unsafe { let this = self.get_unchecked_mut(); this.bar = &mut this.foo; } } pub fn get_foo_mut(self: Pin<&mut Self>) -> Option<&mut usize> { if self.bar.is_null() { None } else { unsafe { Some(&mut *self.bar) } } } } fn foo() -> Pin<Box<Foo>> { let foo = Foo::new(1); let mut foo = Box::pin(foo); foo.as_mut().init(); foo } fn main() { let mut f = foo(); let foo_mut = f.as_mut().get_foo_mut(); if let Some(foo_mut) = foo_mut { *foo_mut = 5; println!("{}", *foo_mut); } }
여기에서 Foo 구조체의 _pin 필드가 왜 존재하는지 의문일 수 있습니다.
marker 타입 PhantomPinned를 사용하여 Foo를 !Unpin으로 만들어줍니다.
(Send 처럼 !Send를 구현할 수 있도록 하는 기능은 아직 지원하지 않습니다.)
Box<T> 또한 Unpin이기 때문에, Pin<Box<T>>으로 래핑 하였습니다.
Pin을 사용한 타입들은 항상 고정된 주소를 가지게 되었고, bar도 Pin을 사용하여 초기화 되었습니다.
그렇기에 Pin<Box<Foo>>를 Pin<&mut Foo> (as_mut)로 만드는 건 안전합니다.
추가적으로 Pin<T>을 사용할 때 조건이 있습니다:
T가Unpin이면,T는Pin에 의해 소멸될 때까지T를Unpin상태로 유지해야 합니다.T가!Unpin이면,T는Pin에 의해 소멸될 때까지 고정됩니다.
Unpin을 구현하면 Pin이 &mut T를 안전한 러스트에서 허용해주며, 그렇지 않으면 안전한 러스트에서 고정할 수 있습니다. (즉 &mut T를 얻을 수 없음).
때문에 아래의 코드는 작동하지 않습니다:
use std::{mem::*, pin::*}; fn swap_data<T>(x: Pin<&mut T>, y: Pin<&mut T>) { swap(&mut *x, &mut *y); // <- cannot borrow data in dereference of `std::pin::Pin<&mut T>` as mutable } fn main() { let mut x = 5; let mut y = 10; let x = Pin::new(&mut x); let y = Pin::new(&mut y); swap_data(x, y); }
그럼 이런걸 어디에 쓸까요? 이는 Future에서 사용하는데 (사실상 여기서만 사용), Future은 이 글에서 자세히 다루진 않으나, 비동기에서 사용하는 중요한 개념입니다.
RwLock, 그리고 Mutex의 차이점
한번쯤 들어본 RwLock은 Mutex(상호 배제)와 비슷해 보입니다.
RwLock는 Reader-Writer Lock의 줄임말입니다.
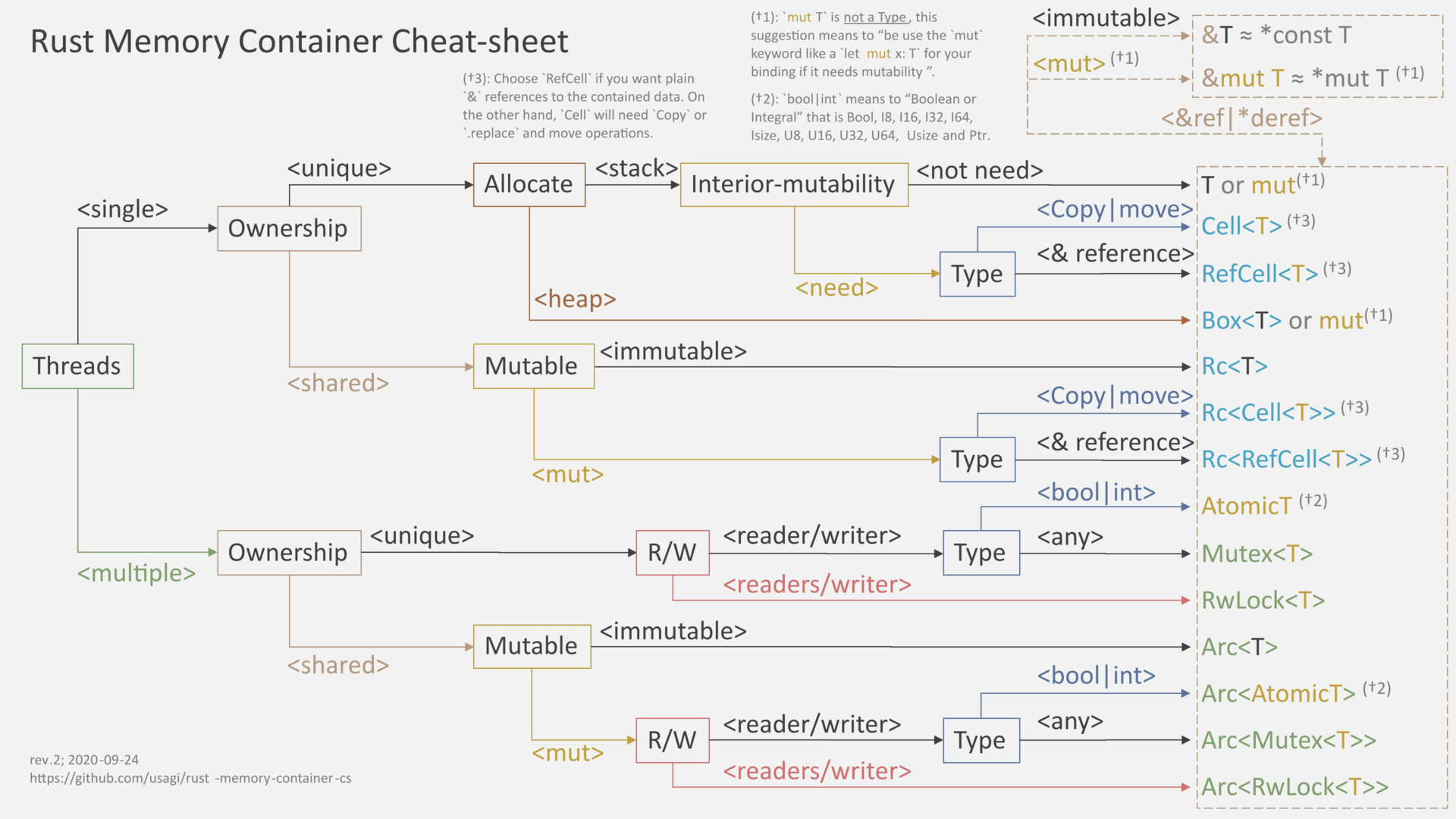 (출처: https://github.com/usagi/rust-memory-container-cs)
(출처: https://github.com/usagi/rust-memory-container-cs)
이 자료에서 볼 수 있듯이 Mutex는 Reader / Writer이며, RwLock은 Readers / Writer 입니다.
Mutex는 동기화이며, RwLock은 그렇지 않습니다. 여기서 Lock의 의미는 다음과 같습니다:
Write Lock:Writer가 쓰기를 마칠 때까지Reader가 읽을 수 없습니다.Read Lock:Reader가 읽을 때 까지Writer가 값을 수정할 수 없습니다.
Mutex는 lock을 호출하는 시점에서 자신의 차례가 올 때까지 기다립니다.
(unlock, lock 함수가 반환하는 MutexGuard가 Drop 되면 자동으로 unlock 됩니다.)
또 한가지가 더 있습니다.
RwLock<T>는 Mutex<T>에 비해 T가 thread-safe를 위해 구현해야 할 트레잇 바운드가 더 많습니다:
Mutex:T: SendRwLock:T: Send + Sync
즉, 동기화를 위한 API는 Mutex가 유일합니다.
Mutex와 RwLock의 API를 보면 차이점이 이해될 수 있습니다:
Mutex에서 값을Write/Read(이하R/W) 하려면lock을 호출하여MutexGuard스마트 포인터를 얻습니다.
이를 역참조하여, 값을R/W할 수 있습니다.MutexGuard는Deref가 구현되어 있으니 스마트 포인터입니다. (이런 구조를RAII패턴이라 칭합니다.)
즉, 정확히는Mutex가 스마트 포인터가 아닌MutexGuard가 스마트 포인터입니다.
RwLock은write()와read()를 통해 각각RwLockWriteGuard와RwLockReadGuard를 얻습니다.
이 둘도 위와 같이 스마트 포인터 이며, 이들도 역참조를 통해 값을R/W할 수 있습니다.
물론
lock(),write(),read()를 호출하면Result<T, E>를 반환합니다. 이해를 돕기 위해 위와 같이 설명했을 뿐이죠.
아래의 예제를 보며, Mutex와 RwLock이 어떻게 작동하는지 확인해봅시다:
use std::{ sync::{Arc, Mutex}, thread, time::Duration, }; fn main() { let x = Arc::new(Mutex::new(0)); let t1 = thread::spawn({ let x = Arc::clone(&x); move || { let mut x = x.lock().unwrap(); *x += 1; println!("t1 (write): {}", *x); thread::sleep(Duration::from_secs(1)); } }); let t2 = thread::spawn({ let x = Arc::clone(&x); move || { let x = x.lock().unwrap(); println!("t2: {}", *x); thread::sleep(Duration::from_secs(1)); } }); let t3 = thread::spawn({ let x = Arc::clone(&x); move || { let x = x.lock().unwrap(); println!("t3: {}", *x); thread::sleep(Duration::from_secs(1)); } }); t1.join().unwrap(); t2.join().unwrap(); t3.join().unwrap(); }
이 예제는 Mutex를 사용하는 예제입니다.
실행해보면 t1이 출력되며, 1초를 기다린 후 t2, 또다시 1초를 기다린 후 t3가 출력되었습니다
이는 Mutex가 동기화라는 것을 알 수 있습니다. R/W를 하나 밖에 하지 않기 때문에 lock을 호출하여 MutexGuard 스마트 포인터를 가져온 후, 역참조 하여 값을 수정하고 읽었습니다.
RwLock
조금만 수정하여 RwLock을 사용하는 예제를 작성해봅시다:
use std::{ sync::{Arc, RwLock}, thread, time::Duration, }; fn main() { let x = Arc::new(RwLock::new(0)); let t1 = thread::spawn({ let x = Arc::clone(&x); move || { let mut x = x.write().unwrap(); *x += 1; println!("t1 (write): {}", *x); thread::sleep(Duration::from_secs(1)); } }); let t2 = thread::spawn({ let x = Arc::clone(&x); move || { let x = x.read().unwrap(); println!("t2: {}", *x); thread::sleep(Duration::from_secs(1)); } }); let t3 = thread::spawn({ let x = Arc::clone(&x); move || { let x = x.read().unwrap(); println!("t3: {}", *x); thread::sleep(Duration::from_secs(1)); } }); t1.join().unwrap(); t2.join().unwrap(); t3.join().unwrap(); }
이 예제를 실행해보면 t1이 출력된 후, 1초 뒤에 동시에 t2, t3 (이 둘의 순서는 상관없습니다. 동시에 출력되었기 때문이죠.)이 출력되었습니다.
그리고 1초 후 프로그램이 종료되었습니다. 이렇듯 RwLock은 동기화되지 않습니다.
실제로 같은 코드 내에서 Mutex의 lock을 동시에 실행하면, 데드락(deadlock)이 발생합니다:
use std::sync::{Arc, Mutex}; fn main() { let x = Arc::new(Mutex::new(0)); { let x1 = x.lock().unwrap(); let x2 = x.lock().unwrap(); } }
이 예제는 영원히 끝나지 않습니다.
하지만 예제를 RwLock을 사용하는 방법으로 변경하면, 프로그램이 정상적으로 끝나는 것을 확인할 수 있습니다:
use std::sync::{Arc, RwLock}; fn main() { let x = Arc::new(RwLock::new(0)); { let x1 = x.read().unwrap(); let x2 = x.read().unwrap(); } }
atomic 타입과 Ordering 열거형
보통 빌드한 프로그램을 실행하면 인간이 느끼기엔 빠르게 느껴집니다. (항상 그런건 아닙니다.)
근데 컴퓨터(하드웨어)는 그렇지 않습니다:
특히 램(RAM)은 생각보다 느립니다. 실제로 봐도 CPU와 램은 떨어져있죠.
이들이 데이터를 주고받느라(사이클) 꽤 많은 사이클을 소비합니다. <-- 이건 손해죠.
CPU는 어떠한 연산을 1번만에 처리하는 반면, 램과 데이터를 주고받느라 여러 사이클을 돌려야 하기 때문입니다.
그럼 어떻게 해야할까요?: 램은 CPU에 박아 넣으면 됩니다. (물리적으로)
CPU 마다 다르겠지만, CPU의 구조는 대충 이렇게 생겼습니다:
MC (Memory Controller): 램과 소통하는 역할입니다. 여기서 램 슬롯 등을 제어합니다.Core:CPU의 그 코어가 맞습니다.Cache: 우리가 찾던CPU에 박혀있는 램입니다. (물리적으로Core보다 더 큰 사이즈를 가지고 있습니다.) (L1,L2,L3등)- ... 그리고
misc(minimal instruction set computers),qpi(quick path interconnect) 등이 있습니다. 우리가 알아야할 것은 아닙니다.
Cache (캐시) 부분을 봅시다: L1은 8~64KB 정도로 제한됩니다. L2와 L3는 이것보다 더 크며, L3는 8MB 정도 됩니다.
우리가 생각하는 8GB 정도의 램은 아닙니다. 그러니깐 이름이 캐시 메모리죠.
아무튼 캐시를 사용하면, 램의 사이클보다 더 적은 사이클로, 빠르게 처리할 수 있습니다.
CPU가 특정 주소의 데이터에 접근하면, 먼저 캐시에서 찾습니다.
있으면 그 값을 읽고 (cache hit), 없으면 램에 접근합니다. (cache miss)
그리고, 그 값을 캐시에 저장합니다.
그런데 캐시는 상당히 제한되어있습니다. 당연하겠지만, CPU는 자주 접근하는 주소를 모르기 때문에, 그냥 무식하게 다 찼으면 CPU 마다 다른 방식으로 처리합니다.
여기서 등장하는 다른 용어가 있습니다: CPU 파이프라이닝 (pipelining)입니다. 매우 간단하게 설명하자면, 병렬 처리를 위해 존재합니다
예를 들어, 4단계의 어떤 사이클이 있다고 생각합시다. 한 사이클을 돌고 다른 사이클을 실행하는 것 보단, 동시에 실행하는 것이 효율적일 것입니다.
방금 CPU 명령어 실행 사이클을 말했습니다. CPU의 명령어 실행 사이클은 다음과 같습니다:
fetch: 명령어를 읽음decode: 명령어 해석execute: 명령어 실행write: 결과를 씀
또 이상한게 있습니다. 컴파일 시 명령어 재배치가 일어날 수 있습니다. 말 그대로, 명령어가 재배치가 되는 경우입니다.
아마 그 코드는, 재배치가 되던 안되던 같은 값을 반환하며, CPU 파이프라이닝을 효율적으로 하기 위해 명령어 재배치가 일어났을 것입니다.
(참고로 godbolt 같은 곳에서 이를 재현하려 하면, 명령어 재배치가 일어나지 않을 수 있습니다. 이는 CPU 마다 다릅니다.)
그런데 이렇게 지 마음대로 수정해버리면, 그것이 제대로 작동한다는 보장이 있을까요? 이를 해결하기 위해, 수정 순서(modification order)가 존재합니다. 이는 어떤 값에 대한, 값의 변화를 기록합니다.
예를 들어, 변수 foo를 선언하고, 3개의 스레드 A, B, C를 동시에 실행합니다.
A 스레드:foo에1을 대입. 그리고 약간의 딜레이 후,foo에2를 대입: 이때의 수정 순서는1 -> 2가 됩니다.B 스레드:foo에3을 대입. 그리고foo를2번 읽음: 이때의 수정 순서는3 -> 4 -> 2가 됩니다.C 스레드:foo를 읽음. 그리고foo에4를 대입. 그리고foo를 읽음: 이때의 수정 순서는1 -> 4 -> 2가 됩니다.
좀 복잡하게 설명했지만, 우리가 볼 것은 다음과 같습니다:
만약 어떤 스레드가 3을 읽었다면, 다음엔 3, 4, 2 중 하나가 읽합니다.
위에서 서술하지 않는 내용이 있는데, 바로 캐시는 코어마다 가지고 있습니다. (ex, Core 1의 L1, L2, L3)
만약 캐시에서만 3을 기록하고 있다면, 다른 코어에선 그 값이 3 인 것을 보장할 수 없습니다.
즉, 동기화 작업은 리소스가 시간을 많이 소비하는 작업입니다.
atomic
서론이 좀 길었는데, 본론으로 돌아와 atomic에 대해 알아봅시다.
C++를 배워보았다면, atomic을 어느 정도 알 것입니다. 사실상 러스트의 atomic은 C++의 atomic을 구현한 것입니다.
atomic은 원자적 연산 (한 번에 일어나는 명령어 연산) 입니다. 1개의 명령어 이므로, 처리했다와 안했다로만 존재합니다.
(어셈블리어 코드에 lock 접두어가 포함되게 되는데, lock은 CPU 명령어 실행 사이클을 한번에 처리합니다.)
atomic을 사용하는 예제:
use std::{ sync::{atomic::*, *}, time::*, *, }; fn main() { let spinlock = Arc::new(AtomicUsize::new(1)); let t = { let spinlock_clone = Arc::clone(&spinlock); thread::spawn(move || { while spinlock_clone.load(Ordering::Relaxed) == 1 { hint::spin_loop(); thread::sleep(Duration::from_secs(2)); spinlock_clone.store(3, Ordering::SeqCst); } }) }; while spinlock.load(Ordering::SeqCst) != 3 { hint::spin_loop(); if spinlock.load(Ordering::SeqCst) == 3 { println!("{}", spinlock.load(Ordering::SeqCst)); } } t.join().unwrap(); }
Spin Lock은 다른 스레드가 어떤 리소스를Lock하고 있다면, 현재 스레드를 기다리고, 락이 풀리면 현재 스레드가 그 리소스에 접근하는 동기화 기법입니다. 자세한 내용은 이 글에서 다루지 않습니다.
Ordering
위 코드에서 처음 보는 것들이 많이 등장했습니다: 바로 Ordering 열거형입니다.
Relaxed (store, load, modify): 가장 느슨한 조건입니다. 즉, 다른 메모리 접근들과 순서가 바뀌어도 무방합니다. 아무런 제약이 없으므로,CPU마음대로 재배치가 가능합니다. (결과가 동일하다면)Release (store, modify), Acquire (load, modify):Relaxed는 아무런 제약이 없어서, 사실상Atomic을 쓸 이유가 없어집니다.Release와Acquire는 그것보단 조금 더 엄격합니다:Release는 재배치를 금지합니다.Acquire로 읽는다면,Release이전의 명령어들이 스레드에 의해 관찰될 수 있어야 합니다.AcqRel (modify):Acquire+ReleaseSeqCst (store, load, modify):SeqCst는 순차적 일관성(Sequential Consistency)을 보장합니다. 쉽게 말해서 재배치도 없고 모든 스레드에서 동일한 값을 관찰할 수 있습니다. 대신 동기화 비용이 클 수 있습니다.
또한, store와 load 함수는 atomic 객체에 대해 쓰기 및 읽기를 가능케 하는 함수입니다. 이 함수의 인자에 Ordering 열거형이 전달됩니다.
그런데 우린 의문점이 하나 있습니다: "왜 Atomic은 제네릭(Atomic<T>)을 사용하지 않는가?" 이겠죠.
C++에서도 클래스 템플릿을 사용하여, atomic을 제네릭으로 사용할 수 있습니다. (atomic<T>)
그 이유는 생각보다 간단한데, 예를 들어, Atomic<[usize; 3]> 같은 건 하드웨어가 지원하지 않습니다.
이것의 해결법은 atomic 크레이트나 Mutex<T>를 사용하는 방법이 있습니다. 물론 둘 모두 Atomic의 작동 방식과는 다르긴 합니다.
Atomic은 하드웨어와 동시성 프로그래밍을 둘 다 이해하고 있어야 함으로, 상당히 어려운 개념에 속합니다.
이해하지 못했다면, 그냥 Mutex<T>나 RwLock<T>을 쓰는것이 올바른 선택입니다.
#[repr(...)] 속성
#![allow(unused)] fn main() { struct Foo { x: i32, y: i16 } }
얼핏 보기엔 Foo의 크기는 6바이트 (32비트 + 16비트 (= 48비트))가 되야하지만, 실제론 8바이트가 됩니다.
이는 구조체가 메모리 상에 어떻게 저장되는지 알아야하는데, 결론부터 말하자면 6바이트가 아닌 8바이트가 되는 이유는 메모리 상에서 패딩을 적용하기 때문입니다.
패딩은 NULL 데이터가 삽입된것이며, 최대 크기인 x (32비트 = 4바이트)의 크기와 맞추기위해 y에 3 바이트(=24비트)의 패딩이 삽입되었습니다. 즉, y의 크기는 4바이트가 되었습니다.
이렇게 패딩을 넣어주는것이 메모리 정렬인데, 메모리 정렬이 필요한 이유는 CPU에 있습니다.
컴퓨터는 데이터를 쓰거나 읽을때, 워드(WORD) 단위로 처리됩니다.
CPU 마다 다르긴 하지만, 1 WORD는 4바이트를 가집니다. 즉, 컴퓨터는 메모리를 4바이트 단위로 처리하죠.
처음에 본 Foo 구조체를 살펴봅시다.
첫번째 경우: 원본 (6 바이트)
x32비트 +y16비트 (= 48비트 = 6바이트)
만약 Foo의 데이터들이 0x03 부터 0x08 까지 메모리에 저장되어 있다고 가정해봅시다.
00 01 02 03 | 04 05 06 07 | 08 09 0A 0B | 0C 0D 0E 0F
└──────────────────┘
CPU는 데이터를 처리하려면 WORD (= 4바이트) 단위로 처리해야합니다. 때문에 CPU는 총 3번의 메모리 접근을 해야합니다.
두번째 경우: 패딩 적용 (8 바이트)
x32비트 +y(16비트 + 패딩 16비트 (= 32비트)) (= 64비트 = 8바이트)
이 경우엔 데이터가 정렬되었고, 때문에 메모리 상에 다음과 같이 저장됩니다.
00 01 02 03 | 04 05 06 07 | 08 09 0A 0B | 0C 0D 0E 0F
└───────────────────────┘
이 경우엔 CPU는 총 2번의 메모리 접근을 해야합니다.
이처럼 위와같은 상황에선 두번째의 경우가 더 효율적입니다.
즉, 정렬을 위해선 1 WORD의 배수 크기로 데이터를 저장하면 됩니다. 즉, 구조체의 크기는 구조체에서 가장 큰 데이터의 크기의 배수가 됩니다.
#[repr(..)] 속성
#[repr(..)]은 구조체 또는 열거형의 메모리 레이아웃을 지정할 수 있는 속성입니다.
메모리 레이아웃은 크기, 정렬, 패딩 등이 포함됩니다.
#[repr(C)]: C/C++의 레이아웃을 따릅니다. 이는 FFI를 사용할때 유용합니다.#[repr(packed)]: 패딩을 하지 않습니다. 이는 메모리 절약을 위해 사용되나, 앞서 말한 메모리 정렬이 필요한 상황에선 부정적인 영향이 있을 수 있습니다.#[repr(transparent)]: 타입의 레이아웃을 필드 타입의 레이아웃으로 설정합니다. 필드는 하나만 제공되어야하며,ZST(Zero Sized Type)가 아니어야 합니다.#[repr(align(n))]: 타입의 정렬을n으로 설정합니다.n은 2의 거듭제곱이어야 합니다.#[repr(u*)],#[repr(i*)]: 필드가 없는 열거형의 크기를 지정합니다.*은8,16,32,64,128입니다.
하나의 예시로, #[repr(u8)]을 사용하여, 열거형의 크기를 1바이트로 지정할 수 있습니다.
#[repr(u8)]
#![allow(unused)] fn main() { #[repr(u8)] enum Color { Red, Green, Blue, } impl From<Color> for u8 { fn from(color: Color) -> u8 { unsafe { std::mem::transmute(color) } } } let color = Color::Red; let value: u8 = color.into(); assert_eq!(value, 0); }
#[repr(transparent)]
#![allow(unused)] fn main() { #[repr(transparent)] struct Wrapper<T>(T); assert_eq!(4, std::mem::size_of::<Wrapper<i32>>()); assert_eq!(1, std::mem::size_of::<Wrapper<u8>>()); }
자세한 내용은 nomicon 참조.
Let's write!
Any트레잇에 대한 글은 이곳을 참고해봅시다.
HashMap을 쓰던 Rusty한 하루였습니다.
#![allow(unused)] fn main() { HashMap::from([(1, 2), (3, 4)]); }
from 함수를 사용해서(또는 .into()) HashMap을 생성할 수 있었습니다.
해시 맵이 아닌 json (JavaScript Object Notation) 값을 다루려면 serde-rs/json 등으로 json 값을 다룰 수 있습니다.
필자는 단순한 코드를 원하고, 크레이트를 사용하기 원하지 않았죠.
하지만 러스트에선 자바스크립트 계열 언어(타입스크립트 등)에 존재하는 json 기능이 없습니다.
(자바스크립트도 원래는 JSON이 기본 기능이 아니긴 했습니다.)
그래서 만능 매크로를 선언 해보았습니다.
#![allow(unused)] fn main() { macro_rules! json { ($($key:expr => $value:expr),*) => {{ use std::collections::*; let mut map: HashMap<&str, _> = HashMap::new(); $( map.insert($key, $value); )* map }}; } }
key: value 으로 작성했으면 좋겠지만, 파서의 한계로 => 를 사용하였습니다.
만약
serde-rs/json같은 크레이트와 같은 매크로를 선언하고 싶다면, 절차적 매크로를 사용해봅시다.
이 매크로는 다음과 같이 사용할 수 있습니다:
#![allow(unused)] fn main() { json! { "a" => "foo", "b" => "bar", "c" => "baz" }; }
사실 json이 아닌 HashMap이긴 합니다.
그런데 이것은 심각한 문제가 있습니다: 매크로에서 value 타입을 &str로 단정 짓는 바람에 다른 타입을 쓸 수 없었습니다:
json! {
"a" => "foo",
"b" => "bar",
"c" => 3 // mismatched types
};
Any
이러면 의미가 없으니, 필자는 Any 트레잇을 사용해보았습니다.
Any 트레잇은 모든 타입을 받을 수 있습니다. Any 트레잇은 TypeId와 같이 자주 사용되지만, 이 글에선 다루지 않습니다.
좀 복잡해질 수 도 있기 때문에 json 모듈을 따로 구현해두었습니다.
#![allow(unused)] fn main() { pub mod json { #[macro_export] macro_rules! json { ($($key:expr => $value:expr),*) => {{ use std::{any::*, collections::*}; let mut map: HashMap<&str, Box<dyn Any>> = HashMap::new(); $( map.insert($key, Box::new($value)); )* map }}; } } let json = json! { "a" => 1, "b" => "qwerty", "c" => json! { "d" => [1, 2, 3] } }; }
이제 드디어 모든 타입을 받을 수 있게 되었습니다.
Any 트레잇은 컴파일 시간에 크기를 알 수 없기 때문에, Box<T>를 사용하였습니다.
이제 downcast_ref 또는 downcast_mut으로 값에 접근할 수 있습니다:
#![allow(unused)] fn main() { if let Some(v) = json["b"].downcast_ref::<&str>() { assert_eq!(*v, "qwerty"); } }
값 가져오기
그런데 누가 json 값을 가져오는데 downcast_...같은 복잡한 함수를 쓸까요? 그런건 아무도 안씁니다.
때문에 get 헬퍼 함수 및 가변 downcast 헬퍼 함수 get_mut을 구현해보았습니다.
#![allow(unused)] fn main() { pub mod json { use std::any::*; pub struct JsonValue<T: Any + ?Sized>(pub T); impl JsonValue<dyn Any> { pub fn get<T: Any>(&self) -> Option<&T> { self.0.downcast_ref::<T>() } pub fn get_mut<T: Any>(&mut self) -> Option<&mut T> { self.0.downcast_mut::<T>() } } #[macro_export] macro_rules! json { ($($key:expr => $value:expr),*) => {{ use std::{any::*, collections::*}; let mut map: HashMap<&str, Box<JsonValue<dyn Any>>> = HashMap::new(); $( map.insert($key, Box::new(JsonValue($value))); )* map }}; } } }
JsonValue 구조체를 정의해주었습니다.
제네릭 T는 Any를 바운드하였으며, 컴파일 타임에 알 수 없기 때문에 ?Sized를 붙여주었습니다.
코드는 복잡해 보이지만, 한층 더 편리한 러스트 프로그래밍을 할 수 있습니다.
#![allow(unused)] fn main() { use json::*; let json = json! { "a" => 1, "b" => "qwerty", "c" => json! { "d" => [1, 2, 3] } }; if let Some(v) = json["b"].get::<&str>() { assert_eq!(*v, "qwerty"); }; if let Some(v) = json.get_mut("b") { if let Some(v) = v.get_mut::<&str>() { *v = "foo"; assert_eq!(*v, "foo"); } }; }
번외
Rust가 C++를 대체할 수 있을까?
IT 관련 뉴스를 보다 보면, Rust (러스트) 언어가 자주 언급되는 것을 볼 수 있습니다. 그런 기사를 보면, 여러 기업 (Google, AWS 등)과 프로젝트(Deno, Redox 등)의 개발 언어가 C++에서 Rust로 대체 또는 사용된다는 내용을 볼 수 있습니다. (심지어 Linux 커널에도 러스트가 도입되는 계획이 있습니다.)
아마 "Rust vs C++"가 주제인 논쟁이 자주 벌어지는 이유는, 두 언어의 사용처가 비슷하기 때문이겠죠.
이번 글은 러스트는 C++ 대신 사용하기 좋으며, 정말로 C++를 대체할 수 있을까? 에 대한 글입니다.
들어가기 앞서, 필자는 C++ 전공이 아니기 때문에 틀린 정보가 있을 수 도 있습니다. 이에 대해 반박하셔도 좋습니다.
러스트를 접해보았다면, C++과 상당히 비슷한 부분이 상당히 존재한다는 것을 알 수 있습니다.
안전한 러스트에선 전반적으로 RAII (Resource Acquisition Is Initialization) 패턴을 사용합니다.
이는 C++에서 유래되었습니다.
안전한 러스트
여기서 안전한 러스트는 다음과 같은 보장을 말합니다:
- 소유권과 참조, 수명을 컴파일 타임에 검사합니다.
- 소유권과 수명은 러스트의 가비지 컬렉터를 대신하여, 메모리 관리를 위해 고려된 생소한 개념입니다. (C++에도
unique_ptr등의 소유권 개념이 있긴 합니다만.) - * 소유권과 수명을 이 글에선 서술하지 않습니다. 모든 값은 소유권과 수명을 가지고 있고, 이의 유효성을 컴파일 타임에 검사함으로써, 런타임 시 안전성을 보장한다는 것만 알아둡시다.
- 참조는 후술할 로우 포인터에 몇가지 안전성을 보장하는 시스템을 적용한 러스트의 기능입니다. 최종적으로는 로우 포인터로 컴파일됩니다.
- 소유권과 수명은 러스트의 가비지 컬렉터를 대신하여, 메모리 관리를 위해 고려된 생소한 개념입니다. (C++에도
null이 없습니다. (=null pointer에러가 없습니다.)- 가변성을 컴파일 타임에 검사합니다. 불변의 변수는 수정이 불가능하며,
mut키워드를 통해 가변 변수를 선언할 수 있습니다. - 예외 대신
Result<T, E>를 사용합니다. (패닉(panic)이 존재하나, 디버그 (또는 테스트)가 아니라면, 프로그래머의 잘못이 아닌 이상 발생하진 않습니다.)
안전하지 않은 러스트
러스트가 안전하기만 하다고 서술하지 않고, 안전한 러스트라 서술한 이유는, 고급 기능인 안전하지 않는 (unsafe) 러스트가 존재하기 때문입니다.
안전하지 않는 러스트는 다음과 같은 기능을 가집니다.
- 로우 포인터(
raw pointer)를 역참조 할 수 있습니다. (=null이 발생할 수 있습니다.) - 안전하지 않는 함수 호출할 수 있으며, 안전하지 않는 트레잇을 구현할 수 있습니다.
- 가변 정적 변수를 수정할 수 있습니다. (여기선 다루지 않습니다.)
즉, 러스트는 메모리 안전을 보장으로 하나, 이를 강제하지 않는 안전하지 않는 러스트를 가지고 있습니다.
이 글은 러스트의 unsafe를 다루는 내용은 아니니, 이렇게 2가지의 러스트가 있다는 것만 알아둡시다.
또한 러스트는 C++의 거의 모든 (언어 레벨, 표준 라이브러리) 기능을 가지고 있습니다.
예를 들어, C++의 shared_ptr은 러스트의 Rc<T> (가변일 경우 Rc<RefCell<T>> 등), thread-safe에서 사용할 경우 Arc<Mutex<T>> 또는 Arc<RwLock<T>>) 등이 있습니다.
이를 바탕으로 C++와 러스트를 비교해봅시다:
러스트의 특징과 단점:
- 위에서 설명했듯이, (안전한 러스트에서) 메모리 안전을 보장합니다.
- 가비지 컬렉터가 없습니다.
null이 없습니다.- 병렬 프로그래밍, 함수형 프로그래밍, 시스템 프로그래밍을 지원합니다.
Cargo라는 패키지 매니저로, 강력한 패키지 관리를 지원합니다.- C++에 비해, 문서(자료)가 많이 없습니다.
- 생태계가 C++에 비해 매우 작습니다.
C++의 특징과 단점:
- C 언어의 절차적 프로그래밍을 기반으로 객체지향 프로그래밍, 템플릿 등을 사용하는 일반화 프로그래밍을 지원합니다.
- 러스트와 반대로, 문서(자료)가 많으며, 한국어 자료 또한 매우 많아서, 자료를 참고하기 좋습니다.
- 생태계가 상당히 구축되어있습니다.
- 러스트에 비해 메모리 관리가 어렵습니다 (메모리 안전을 보장하지 않습니다.) (물론 스마트 포인터
unique_ptr(러스트의 소유권과 유사),RAII패턴 등을 이용하면 어느 정도 방지할 수 있긴합니다만,) - 생산성이 안 좋으며, 디버깅 및 유지보수가 힘듭니다.
- 이렇다 할 패키지 매니저가 없습니다. (컴파일러가 러스트 처럼 단일하지 않습니다.)
둘 모두 서술되어있는 항목보다 더 많을 수도 있습니다. 이렇게만 보면, 러스트가 훨씬 좋아 보이는데, 그런데도 왜 아직까지 러스트보다 C++이 더 많이 쓰이는 걸까요?
러스트의 생태계
위에서 말한 대로, 러스트는 C++에 비해 생태계가 매우 매우 작습니다. 이 뜻은 문서(자료), 커뮤니티 등이 C++에 비해 부족하다는 뜻이며, 결국 이는 이번 주제 (C++ vs Rust)에서 결정적인 증거가 됩니다.
여러 러스트 사용자들이 생태계를 구축하기 위해, 노력하고 있긴합니다.
당장 한국만 해도 한국 러스트 사용자 그룹, Rust Book 한국어 번역 등의 노력이 보이긴 하나, C++에 비빌정도는 택도 안됩니다.
절대 C++를 대체할 수 없는 것일까?
그럼 러스트는 절대 C++를 대체할 수 없는 것일까요? 이건 또 아닙니다.
C++는 사실상 완벽한 생태계를 가지고 있고, 러스트는 생태계를 구축하는 중입니다.
이 뜻은 러스트가 C++를 충분히 대체할 수 있다는 얘기와 같습니다. 생태계가 작긴 하지만, 러스트는 표준 라이브러리 및 언어 문서화가 상당히 잘 되어있습니다.
그럼 영어도 능숙하게 할 수 있고, 메모리 안전성도 보장하고 싶으니, 러스트를 쓰겠다고 하는 사람도 분명 있겠죠. 언어의 선택은 본인의 자유이며, 언어마다 각자 장단점이 있긴 하지만, 러스트와 C++에 대해 한 가지만 말하고 글을 끝내겠습니다.
러스트는 메모리 안전을 보장으로 합니다. 하지만 그것에 완벽하다는 것은 아닙니다:
또한 C++은 발표된 지 무려 37년이 넘은 언어입니다. (러스트는 첫 릴리즈가 12년 전) 그런데도 메모리 안전성을 보장하지 않는 C++를 37년이 넘게 써왔습니다.
결국 이것은 프로그래머들이 큰 문제없이 써왔다는 것이며, 이는 곧 프로그래머에 따라, 메모리 안전을 보장할 수 있다는 뜻으로 해석할 수 있습니다. C++가 잘못된 언어가 아납니다. 러스트가 완벽한 언어는 아니며, 모든 언어는 장단점을 가지고 있습니다.
대기업 또는 큰 프로젝트에서 러스트로 대체한다는 건, 러스트의 장점에 반한 경우이며, 아직 C++로 작성되어있는 (또는 작성될) 프로젝트는 이보다 더 많습니다. (심지어 러스트로 대체한다는 계획을 절대 세우지 않는 프로젝트도 있을 겁니다.)
지금 당장은 러스트는 C++를 대체하기엔 어렵습니다. 하지만, 앞으로의 상황을 우린 알지 못합니다. 언젠간 러스트의 생태계가 커지고, C++를 대체하는 날이 올 수 도 있을겁니다.
이 주제에 대해 중립을 띄고 싶다면, 둘다 배워두시는 것도 좋은 방법입니다.
not available
해당 문서의 일부는 ky0422 티스토리 블로그의 일부 글을 옮겨왔습니다.
모든 컨텐츠는 CC BY-SA 4.0 라이센스를 따릅니다.
빠른 이해를 돕기 위해, 상황에 따라 일부 코드를 생략합니다. 예를 들어 아래와 같은 코드는
#[derive(Debug)] struct Foo(i32, i32); fn main() { println!("{:?}", Foo(1, 2)); }
#![allow(unused)] fn main() { // 생략 println!("{:?}", Foo(1, 2)); }
등으로 표시할 수 있습니다.